Table of Contents

I’m Camille. Last week I was doing what I do on slow mornings — scrolling through the Artificial Analysis Video Arena, checking which models had moved up or down. A name I’d never seen was sitting at the very top of both text-to-video and image-to-video. HappyHorse-1.0. No team page I could open. No paper. Links that said “coming soon.”
If you make product videos, brand content, or any kind of AI-generated visuals for a living, and a pseudonymous model beating Seedance 2.0 and Kling 3.0 sounds like it deserves a closer look — same. This piece is a grounded walkthrough of what’s actually confirmed, what’s only claimed on marketing pages, and what the I2V numbers might mean if you work with reference images every day.
Let’s separate the signal from the rumor.
What Artificial Analysis has actually confirmed
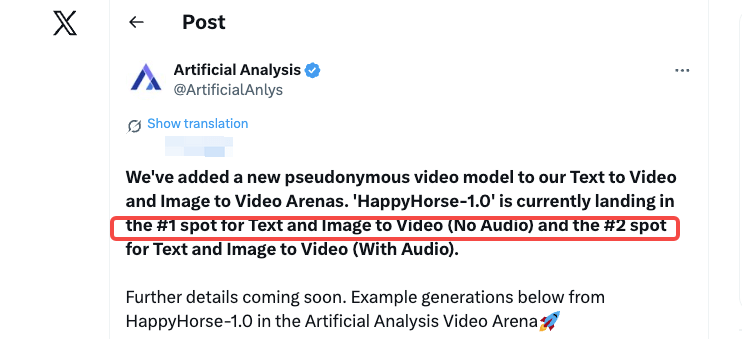
The one hard fact we have is this: on April 7, 2026, Artificial Analysis announced on X that they had added a new model to their Video Arena, using the exact word “pseudonymous.” That word matters. It means the submission came in without a verifiable team, organization, or paper attached. No marketing, no lab self-reporting — just a model generating outputs that blind users kept voting for.
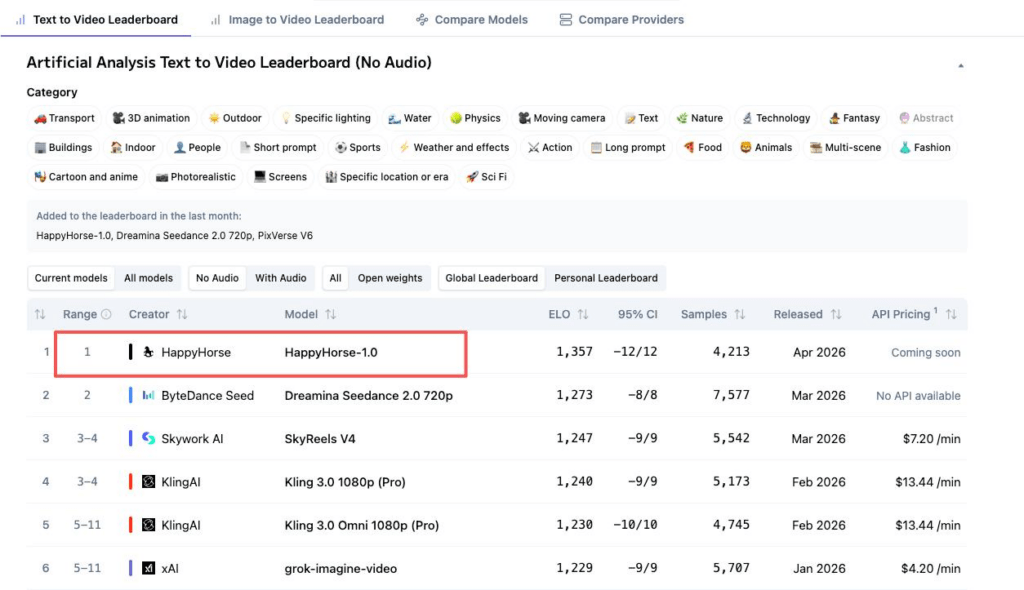
The current positions, which I just re-checked on the Artificial Analysis Text-to-Video leaderboard and Image-to-Video leaderboard:
- T2V, no audio — HappyHorse-1.0 at Elo ~1364, ahead of Dreamina Seedance 2.0 at 1269 and Kling 3.0 Pro at 1244.
- I2V, no audio — HappyHorse-1.0 at Elo ~1399, leading the entire board.
- With audio — Seedance 2.0 edges ahead in both audio categories, by very slim margins.
Quick honesty note: these scores update live. By the time you read this, they will have shifted. Elo for newly added models is more volatile than established ones, and nobody has published HappyHorse’s vote sample count. Seedance has 7,500+ votes behind its number. Past me would have taken a two-day-old leaderboard reading as gospel — current me knows better.
What multiple sites claim — and what I can’t verify yet
Here’s where things get a bit murky. A cluster of sites — happyhorse-ai.com being the most prominent — describe the same model with the same specs: a 15-billion-parameter single-stream Transformer, 40 layers, joint video-and-audio generation in one forward pass, 7-language lip-sync, ~38 seconds for a 1080p clip on an H100, fully open sourceunder a commercial-use license.
Those specs are plausible. They’re also unverified. As of publish date, the GitHub and Hugging Face links on those sites still return “coming soon” or 404. No public API. No downloadable weights. No documented pricing. A separate marketing claim attributes the team to a group “formerly of Alibaba’s Taotian Group, led by Zhang Di (ex-Kling AI),” which a Morningstar / Access Newswire press piece also echoes. Treat that as a claim, not a fact.
Community speculation on X has cycled through WAN 2.7, DeepSeek, Tencent, and most persistently a Sand.ai open-source project called daVinci-MagiHuman, whose specs line up suspiciously well with HappyHorse’s. Nothing has been officially confirmed. A recent analysis from Barchart lays out the attribution question pretty honestly — the most widely reported theory, not confirmed fact.
Bottom line: the leaderboard numbers are real. The team, the weights, the release timeline — pending.
Why I2V users should actually pay attention
Here’s the part that stopped me. HappyHorse’s I2V (no audio) Elo of ~1399 is the highest number on the entire board, higher than its own T2V score.
What that tells me, reading between the lines of blind user votes: when creators upload a reference image and compare two outputs side by side, HappyHorse’s result wins more often. The model seems to follow the reference more closely — subject identity, composition, visual coherence. For anyone making product videos or brand content where the motion absolutely has to respect the source image, reference-following is the metric that matters most. Beautiful motion that drifts from your product shape is useless. Locked-on motion that moves your subject convincingly is worth paying for.
And here’s the thing that’s true for HappyHorse, Seedance, Kling, and every I2V model that comes after: input image quality sets the ceiling of the output. Dirty edges, leftover halos, compression artifacts — the model reads all of that as signal and amplifies it into motion flicker. I stepped into this hole already, so you don’t have to. Before blaming the prompt, check the asset. Mm, that usually saves me an hour.
Known limits and open questions
A few things worth being honest about before anyone rearranges their pipeline around a ranking:
- No public access under the HappyHorse name as of late April 2026. Third-party demo sites exist but aren’t the model developer.
- Elo scores will shift as vote counts grow. Always recheck the live leaderboard.
- Audio is not the leading track. If your workflow needs voiceover, ambient sound, or lip-sync, Seedance 2.0 is a tie or slightly ahead.
- Clip length is short — current outputs are optimized around 5–8 seconds.
FAQ
Is HappyHorse-1.0 made by ByteDance, DeepSeek, or Tencent?
No evidence of any of those. Artificial Analysis called it “pseudonymous.” The most persistent community claim points toward an Alibaba-lineage team, but nothing has been independently verified.
Can I use HappyHorse-1.0 for commercial video today?
Not directly. No public API, no weights, no pricing under the HappyHorse name. Third-party demo sites have their own terms.
Does input image quality affect HappyHorse output?
Yes — every I2V model amplifies input flaws. Clean edges and high-resolution sources matter more than prompt rewriting. This will be true whenever HappyHorse becomes accessible.
How often do Artificial Analysis Elo scores change?
Continuously. A #1 model today can be #3 next week as newer entries collect votes. Always check the live board rather than any article, including this one.
Alright. A model nobody can name is at the top of the most credible video benchmark we have, and the gap between confirmed and claimed is still wide. My take: keep it on your radar, verify before you commit, and don’t let hype decide your workflow for you.
See you next time — may your reference images stay clean.
Previous posts:
Seedance 2.0 Audio Guide: Dialogue, SFX, BGM, and Lip Sync Tips
AI Image to Video Online: Turn Any Photo Into a Motion Clip (Free)
Seedance 2.0 Image to Video: Turn One Photo Into a Consistent 16s Clip